L1 regularization from a bayesian perspective
In one of my last posts, I talked about why we minimize the squared error and how can we derive the usual equations using the Bayesian framework. In this post, I’ll extend the ideas presented there and show how we can interpret lasso regularization from the Bayesian perspective.
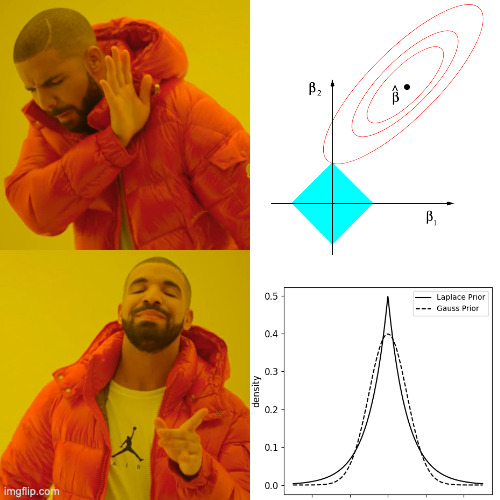
During an interview process, I was asked why lasso regularization introduces sparsity. I explained the typical diagrams (Figure 1) from Elements of Statistical Learning (ESLII) and moved on. However, after the interview, I kept wondering if there was any other explanation for this effect, but I couldn’t find any other satisfactory explanation. Also, I was a little bit tired of the typical explanation using the diagrams from ESLII, so I decided to develop an intuition about lasso sparsity using other explanations. I didn’t find the usual explanation completely satisfactory because my visual intuition is not very good.
Fast forward to last month, when I started reading the “Deep Learning” book, by Goodfellow et al. The book covers the Maximum A Posteriori (MAP) method, which helped me to understand lasso regularization from another perspective.
Regularization as Constraints
In machine learning, we want to solve the optimization problem
\[\text{argmin}_\theta \; L(\mathbf{y}, f(\mathbf{X}, \theta))\]where \(L\) is the loss function, \(\mathbf{y}\) is the vector of true values, \(\mathbf{X}\) is the matrix of features, and \(f(;\theta)\) is a model defined by parameters \(\theta\).
This equation means that we want to find the parameters \(\theta\) such that the model can predict the best possible observed data. We then expect these parameters \(\theta\) to generalize to unobserved data. However, sometimes our model overfits the training data, and to solve this problem we can add some constraints to the parameters \(\theta\). This kind of method is known as regularization, and helps to avoid overfitting.
One option is to add L1 regularization, which consists in
\[\text{argmin}_\theta \; L(\mathbf{y}, f(\mathbf{X}, \theta)) \; \text{subject to} \; \sum_i |\theta_i| \leq \lambda\]By adding the constraint \(\sum_i \vert \theta_i \vert \leq \lambda\) we’re forcing the coefficients to be smaller than \(\lambda\). And using the Lagrangian form we get
\[\text{argmin}_\theta \; L(\mathbf{y}, f(\mathbf{X}, \theta)) + \beta \sum_i |\theta_i|\]where the relation between \(\beta\) and \(\lambda\) depends on the data. There are multiple techniques to solve this optimization problem, but they’re outside the scope of this post, the important point is that this technique induces sparse parameters \(\theta\). Usually, to explain why L1 regularization induces sparsity the reasoning in ESLII is used, however, this post aims to develop another intuition behind this sparsity.
Regularization as Priors
In the last section, we introduced lasso regularization by forcing our parameters to be constrained. However, the same regularization can be achieved from the Bayesian framework via priors.
Before moving on let me introduce a common technique in Bayesian analysis, the so-called Maximum A Posteriori (MAP) estimation.
MAP
MAP estimation is a technique to obtain a point estimate from the posterior distribution of the parameters \(\theta\). This is, given a prior distribution \(p(\theta)\) and a likelihood \(p(x \vert \theta)\), we can compute the MAP estimate of the parameters \(\theta\) as
\[\theta_{MAP} = \text{argmax}_\theta p(\theta | x) = \text{argmax}_\theta p(x | \theta) p(\theta)\]The idea is that we first assign a priori distribution to our parameters \(\theta\) and a likelihood to our data conditioned to the parameters. Then MAP chooses the point of the maximal posterior probability. You can think about MAP as MLE + priors.
Applying \(\log\) to the above formula we get
\[\theta_{MAP} = \text{argmax}_\theta \log p(x | \theta) + \log p(\theta)\]Laplace prior
In the last section, we showed how to use MAP to get point estimates of the model parameters. In this section, we’ll show that with a specific choice of priors and likelihoods we can get the same results as in this approach. If we choose
- Likelihood:
- \(p(y \vert x, \theta) \propto \exp(-(y - f(x, \theta))^2)\) - as we did in the last post.
- Prior:
- \(p(\theta) = \alpha/2 \exp(-\alpha \vert \theta \vert)\) - aka Laplace Prior .
we get the following expression for the MAP estimate
\[\theta_{MAP} = \text{argmin}_\theta (y - f(x, \theta))^2 + \alpha |\theta|\]which is the same minimization problem as the one in the previous section. However, now we can interpret the regularization term as an effect of the prior distribution. In fact, this was known from a long time ago, and it was published in a paper by Tibshirani in 1996.

Notice that if instead of using the Laplace prior we use the a gaussian prior we would have L2 regularization instead of L1. The Laplace and the Gauss priors look like

From the image above we can see that the Laplace prior has more probability density around zero than the Gauss prior. This gives us intuition about why L1 regularization induces sparse solutions. Of course, this is not proof in the mathematical sense, but it can help to develop an intuition about this concept, and from my experience, it’s better to have a strong intuition rather than knowing by memory all the mathematical proofs in the world.